A quick peek of what's inside:
Live-updating Dashboard
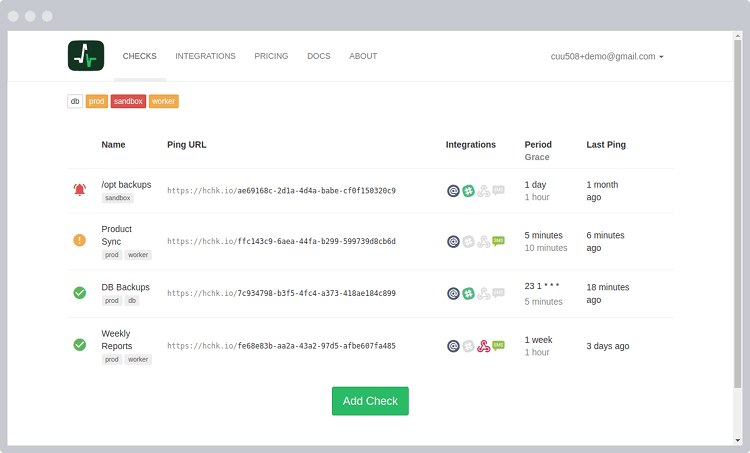
A list of your checks, one for each Cron job, daemon or scheduled task you want to monitor.
Give names and assign tags to your checks to easily recognize them later.
Tap on the integration icons to toggle them on and off.
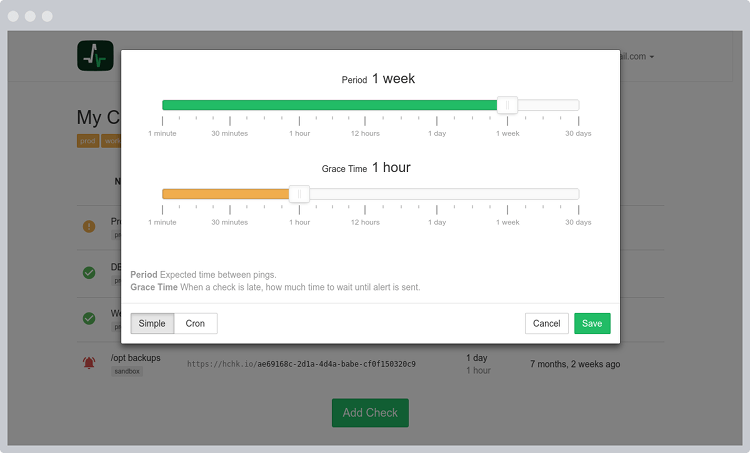
Adjust Period and Grace time to match the periodicity and duration of your tasks.
Simple Configuration
Each check has configurable Period and Grace Time parameters. Depending on these parameters and time since the last ping, the check is in one of the following states:| New. A check that has been created, but has not received any pings yet. | |
| Up. Time since last ping has not exceeded Period. | |
| Late. Time since last ping has exceeded Period, but has not yet exceeded Period + Grace. | |
| Down. Time since last ping has exceeded Period + Grace. When check goes from "Late" to "Down", healthcheck Flip ID sends you a notification. |
Cron Expression Support
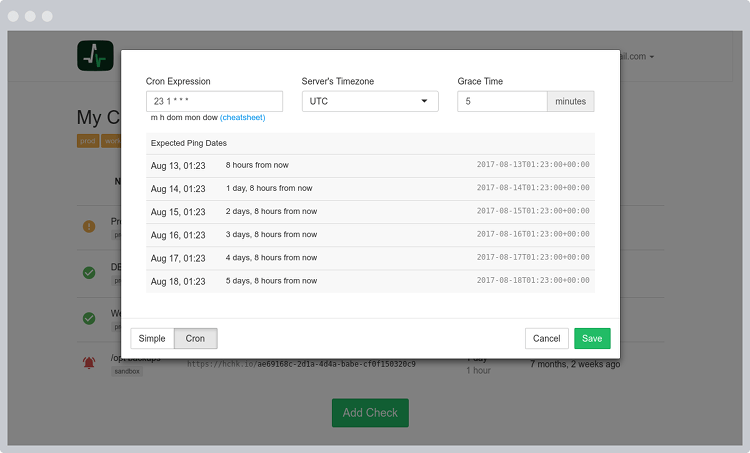
Alternatively, you can define the expected ping dates and times using a cron expression. See Cron Syntax Cheatsheet for the supported syntax features.
Grace Time specifies how "late" a ping can be before you will be alerted. Set it to be a little above the expected duration of your cron job.
Details and Event Log
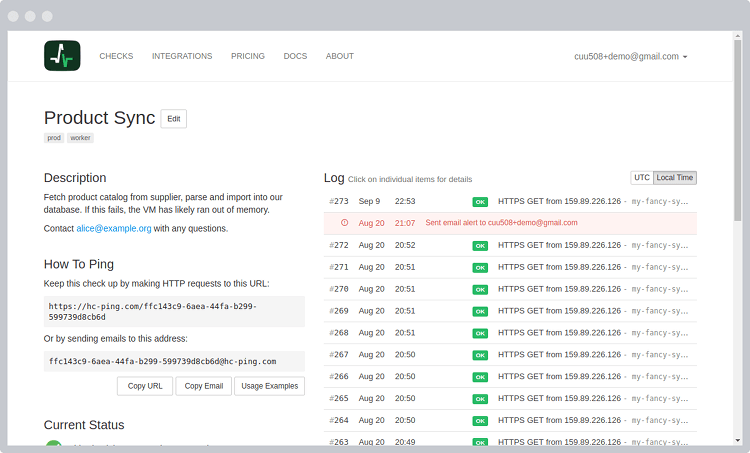
You can add a longer, free-form description to each check. Leave notes and pointers for yourself and for your team.
You can also see the log of received pings and sent "Down" notifications.
Public Status Badges
healthcheck Flip ID provides status badges for each of the tags you have used. Additionally, the "healthcheck Flip ID" badge shows the overall status of all checks in your account.
The badges have public, but hard-to-guess URLs. You can use them in your READMEs, dashboards or status pages.
Integrations
Set up multiple ways to get notified:

Email

Webhooks

Slack
Chat

Mattermost
Chat

Microsoft Teams
Chat

OpsGenie
Incident Management

PagerDuty
Incident Management

PagerTree
Incident Management


Spike.sh
Incident Management

VictorOps
Incident Management

Zulip
Chat
What Can I Monitor With healthcheck Flip ID?
Cron Jobs
healthcheck Flip ID monitoring is a great fit for cron jobs and cron-like systems (systemd timers, Jenkins build jobs, Windows Scheduled Tasks, wp-cron, uwsgi cron-like interface, Heroku Scheduler, ...). A failed cron job often has no immediate visible consequences, and can go unnoticed for a long time.
Specific examples:
- Filesystem backups
- Database backups
- Daily, weekly, monthly report emails
- SSL renewals
- Business data import and sync
- Antivirus scans
- Dynamic DNS updates
Processes, Services, Servers
healthcheck Flip ID monitoring can be used for lightweight server monitoring: ensuring a particular system service, or the server as a whole is alive and healthy. Write a shell script that checks for a specific condition, and pings healthcheck Flip ID if successful. Run the shell script regularly.
Specific examples:
- Check a specific docker container is running
- Check a specific application process is running
- Check database replication lag
- Check system resources: free disk, free RAM, ...
- Send simple, unconditional "I'm alive" messages from your server (or your NAS, router, Raspberry Pi, ...)